
RLWRLD said real-world interaction requires recognizing what to do, maintaining relevant state over time, and grounding decisions in physically meaningful signals. | Source: RLWRLD
RLWRLD last week presented RLDX-1, a new dexterity-first foundation model. The company built the model to tackle complex tasks in the real-world industry using high degree-of-freedom (DoF) robotic hands.
Existing foundation models often lack essential capabilities, such as context memorization or force sensing, required for seamless real-world deployment, according to RLWRLD. To address this, RLDX-1 encompasses the complete robotics lifecycle. It integrates a scalable data-collection pipeline, a versatile architecture design, robust training methodologies, and optimized deployment strategies, said the company.
As a result, RLDX-1 achieves state-of-the-art performance, claimed RLWRLD. The model showcases precision and generalization across both simulated environments and physical industrial applications.
RLWLRD designed the RLDX-1 foundation model from the ground up for dexterous robot hands. Every component exists because a specific failure mode on a real task required them. The result is a single model that can see, feel, remember, and adapt, deployable across single-arm, dual-arm, and humanoid embodiments with high-DoF hands.
RLWRLD identifies five regimes of dexterity
The last mile of industrial automation is dexterity. Today’s robots still cannot reliably pour coffee as the pot grows lighter, pick a moving object off a conveyor, or rotate a hex nut with fingertips, noted Seoul, South Korea-based RLWRLD.
RLWRLD distilled these recurring customer needs into DexBench, a benchmark that organizes them along five regimes of dexterity, where each regime is a specific failure mode of today’s robots.
These five regimes are:
- Grasp diversity: Five-fingered hands are the prerequisite every regime below assumes. RLWLRD has run more than 10 of them in-house. It uses two data pipelines to diversify grasping. Synthetic robot data augments a dataset from a small teleoperation set, while Human Data covers the high-DoF in-hand dexterity that teleoperation cannot reach.
- Spatial precision: The policy must capture sufficient scene structure to place contact correctly before contact is made. RLDX-1 strengthens this capability with a robot-specialized vision language model (VLM) fine-tuned on robot visual question and answering (VQA), where the questions explicitly target the geometric relationship between the robot end-effector and the target object. This training encourages the VLM to better ground object locations and spatial relations that are critical for precise contact placement.
- Temporal precision: A single-frame policy commits to where objects were; by the time the hand arrives, the conveyor object has moved. To address this, the Motion Module extracts motion features from space-time visual correspondences and amortizes multi-frame context into a compact representation. It lets the policy see where and how fast objects are going.
- Contact precision: A coffee pot growing lighter is visually invariant; the signal is in wrist torque. The Physics Module gives tactile and torque their own streams and predicts future contact states alongside actions, so the policy anticipates contact transitions before they happen.
- Context awareness: This is task-level reasoning that wraps around the three precisions. Without it, even a perfectly executed motion is stranded at the single step it was planned for, said RLWRLD. The policy needs memory, recovery, and progress-awareness.
RLDX is built on a multi-stream action transformer
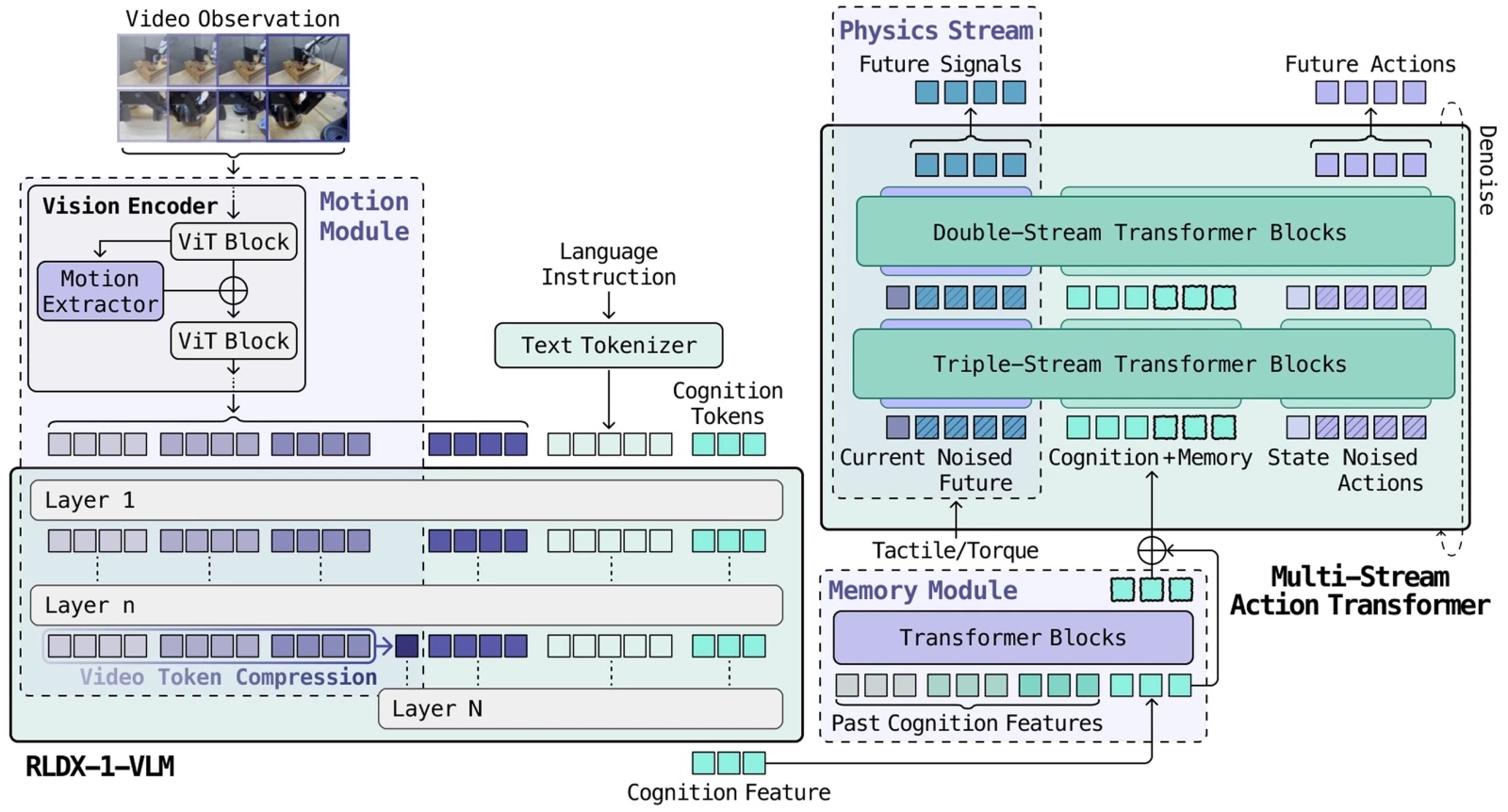
The full RLDX architecture. | Source: RLWRLD
Each regime enters the model as a fundamentally different modality: Torque is a high-rate continuous stream, video is sparse high-dimensional frames, and memory is stateful. In a single conventional transformer, whichever modality dominates the gradient absorbs all the capacity while the rest become decorative.
The architectural answer is Multi-Stream Action Transformer (MSAT). Each modality gets its own processing stream, and cognition tokens compress the VLM output into a fixed-size interface. What follows unpacks each layer. The architecture that holds these modalities together, the data engine that trains it, and the post-training that makes it deployable.
RLDX is built on MSAT, an architecture where each modality gets its own processing stream, and joint self-attention lets them interact.
Existing vision-language-action models (VLAs) fuse modalities inside a single transformer stream, where whichever modality dominates the gradient absorbs all the capacity. MSAT gives each modality its own dedicated processing stream, then lets the streams communicate through joint self-attention without being forced into a shared representation prematurely.
Early blocks keep modalities in parallel streams; later blocks fuse them for action decoding, explained RLWRLD.
RLDX-1 uses a robot-specialized VLM
General-purpose VLMs are strong at visual reasoning, but they do not automatically understand what matters for robot control, RLWRLD asserted. To close this gap, RLDX-1 fine-tunes Qwen3-VL 8B on a robot-trajectory VQA dataset targeting three action-relevant abilities.
First, it targets spatial reasoning about the geometric relationship between the end-effector and target objects. Second is task understanding, which identifies the intermediate subtask implied by the current observation. Third is action grounding that reasons about the low-level action associated with the current frame.
The fine-tuned model, RLDX-1-VLM, serves as the visual reasoning backbone for action generation: +3.42%p over the vanilla VLM on RoboCasa.
A single-frame policy is always one step behind the scene, noted RLWRLD. By the time the hand arrives, the conveyor object has moved. The Motion Module has two complementary pieces.
A video token compression layer feeds multi-frame observations through the VLM, compressing past frames into motion tokens via average pooling, so the model efficiently sees where things are going. A motion learning layer in the vision encoder models spatio-temporal self-similarities (STSS), capturing rotation, velocity, and interaction dynamics directly from visual features.
Together: +37.5%p over GR00T N1.6 and π₀.₅ on performing a pick-and-place task on conveyor belt.
RLDX-1’s Physics Module serves two key functionalities
The Physics Module integrates tactile and torque feedback into RLDX as native modalities. These physical signals are crucial for tasks that require contact-rich object manipulation, primarily serving two key functionalities: weight estimation and contact detection.
For weight estimation, when a robot pours coffee, the module captures weight shifts across both hands to inform RLDX precisely when to stop. For contact detection, a robot needs to identify the exact moment of contact to transition from approaching to picking. While joint angles provide ambiguous information regarding contact timing, torque signals offer distinct, sharp changes at the point of contact.
To fully leverage this, RLDX employs a dedicated stream that not only processes these signals but also predicts future torque states, allowing the policy to possess informative physical embeddings. Furthermore, when such sensors are unavailable, the sensory stream automatically deactivates for graceful degradation to vision-only, allowing a single model to support various hardware setups.
Inside RLDX-1’s cognition interface and memory module
The VLM produces a rich scene understanding, but passing all of its tokens to the action model can be slow and wasteful, said RLWRLD.
The Cognition Interface appends 64 learnable cognition tokens to the VLM’s input. Through attention, they compress the full sequence into a fixed-size representation that carries exactly the information the action model needs. The speed win: +35%p inference speedup (16.3→22.1 Hz).
But these tokens do double duty. The same 64-token representation becomes the unit of long-horizon memory. A FIFO sliding cache stores past cognition features across the rollout, and the Memory Module attends over this cache to track task progress.
Pack a box, assemble a product, or count 10 apples into an opaque bag. Each step depends on knowing what already happened, according to RLWRLD. Compression and memory are the same mechanism, reused, it said.
RLWRLD uses synthetic data to generate what it can’t collect
Real teleoperation alone cannot populate the space a five-finger hand must cover. RLWLRD’s synthetic data pipeline amplifies a small seed set of real demonstrations using video generation models, such as Cosmos-Predict2.
A fine-tuned video model synthesizes new trajectories at scale by varying scene factors. These include lighting, surfaces, positions, and backgrounds.
An inverse dynamics model then annotates the generated videos with action labels, followed by a video quality and motion-consistency filter that retains only instruction-following and physically plausible synthetic data.
Ultimately, RLWRLD said this yields video-action consistent synthetic data that is beneficial for VLA training, rather than merely plausible-looking outputs, with an around five times increase in data scale, leading to a 9.2% gain in average success rate on the GR-1 Tabletop benchmark.
 Submit your session idea for the 2026 RoboBusiness
Submit your session idea for the 2026 RoboBusinessRLWRLD also learns from human hands
There is no better teacher for a dexterous robot hand than a human hand, RLWRLD said. Teleoperation is often too slow and imprecise for five-finger manipulation, as conventional controllers fail to capture the high-speed reflexes required for dynamic tasks like catching or rapid regrasping.
The most adopted alternative, UMI, fits the robotic end effector onto a humanoid, but only for grippers, claimed RLWRLD. It cited DexUMI, which it said ported the recipe to five-finger hands and has not held up in practice: poor ergonomics, constrained hand motion, and a device that must be redesigned for every new robot hand.
RLDX takes the opposite route: record from the bare human hand and close the kinematic and morphological gap in software, with a retargeting framework built for five-finger dexterity.
- The pipeline has four stages, said RLWRLD:
- Track the human hand and object
- Reconstruct the workspace with 3D Gaussian Splatting
- Retarget onto the robot hand
The company said that uses can roll it out in simulation to produce VLA training data. This yields over 200 demonstrations per hour and scales further with automated augmentations, it said.
RLWRLD provides a training pipeline
RLDX is trained through a three-stage pipeline, each stage building on the previous checkpoint. The first is pre-training for general manipulation. The model learns general manipulation knowledge across single-arm, dual-arm, and humanoid embodiments (many equipped with dexterous five-finger hands) through a shared MSAT core with per-embodiment encoders/decoders.
The pre-training mix contains trajectories from diverse real-world datasets and our synthetic robot data. RLWRLD randomly drops embodiment tags so that the model learns both an embodiment-conditioned policy and an embodiment-agnostic one in a single backbone.
Next, it uses mid-training for target embodiments. Starting from the pre-trained checkpoint, the Memory Module and Physics Module are added, initialized from scratch, with existing weights preserved. Embodiment-specific dexterity data builds temporal and sensory capabilities. Pre-training data is partially reused to prevent catastrophic forgetting; Synthetic robot data fill in for data-scarce embodiments.
Finally, it uses post-training for deployment. Imitation learning alone leaves room for improvement for better success rate and optimal motions.
Two mechanisms close the gap, corresponding to the two remaining faces of Context Awareness:
- DAgger (Recovery) focuses training data on the failures the model actually makes. The model is deployed and corrected when it goes out of distribution, and those corrections become new training data. Each iteration narrows the failure distribution until the mistake pattern disappears.
- Progress-Aware RL (Progress-Awareness) is a separate VLM post-trained as a learned progress estimator. Given a trajectory, it predicts how close the policy is to completing the task. This provides reinforcement learning (RL) with a dense, visually-grounded reward signal that drives the policy toward task progress without hand-engineered, task-specific goals. By reusing batch on-policy data, every rollout is fully exploited across multiple updates, making real-robot RL more tractable and affordable.
RLWRLD said its final policy can complete tasks around three times faster than imitation learning alone.
How does RLDX-1 perform against common benchmarks?
RLDX ships as three checkpoints: RLDX-1-PT (pre-trained checkpoint), RLDX-1-MT-ALLEX, and RLDX-1-MT-DROID (8.1B each, mid-trained for their target platforms).
Serving an 8.1B policy in a real-robot control loop in real time is a graph and memory problem more than a FLOPs one. RLWRLD benchmarks RLDX-1-PT in simulation against GR00T N1.5/N1.6 and π₀ [4] / π₀.₅ / π₀-FAST, and also evaluates it on the OpenArm real-world benchmark without any platform-specific mid-training.
The mid-trained checkpoints — RLDX-1-MT-ALLEX, RLDX-1-MT-DROID — are then evaluated on their target platforms. Each benchmark task is designed to isolate a specific axis of dexterity. RLWRLD compares RLDX-1 against strong baseline VLA models, including π₀.₅ and GR00T N1.6.
On the OpenArm + Inspire 6-DoF hand platform, RLWRLD has evaluated RLDX-1-PT, without OpenArm-specific mid-training, to probe how well the embodiment-agnostic pre-trained policy generalizes to a platform it was not specialized for. The benchmark targets versatile intelligence, including object grounding, instruction understanding, and generalization to unseen environments.
RLDX-1 consistently outperforms the baselines on the OpenArm benchmark for versatile intelligence. RLWRLD specified that π₀.₅ performs better than GR00T N1.6 on in-domain tasks, but its performance drops below GR00T N1.6 on out-of-domain tasks, indicating limited generalization to unseen settings.
GR00T N1.6 shows a different limitation. It completely fails on the object identification task, suggesting that it struggles with fine-grained instance-level object grounding, reported the company. In contrast, RLDX-1 maintains balanced performance across different task types without collapsing on any specific capability.
These results indicate that RLDX-1 is not only stronger in average success rate, but also more reliable across the diverse capabilities required for real-world humanoid manipulation, RLWRLD claimed.
Testing RLDX-1 with humanoids
Using the ALLEX humanoid, RLWLRD constructed tasks focused on motion awareness, history awareness, and physical signal awareness, evaluated with RLDX-1-MT-ALLEX specialized for the platform.
The results show a large performance gap between RLDX-1 and existing VLAs. On tasks that require specialized functional capabilities, the major baselines achieve success rates below 30%, while RLDX-1 reaches nearly 90%.
This suggests that existing VLA models still struggle when a task requires more than generic visual-language understanding, such as tracking motion, using history, or interpreting physical signals. In contrast, RLDX-1 can handle these capability-specific challenges much more reliably.
RLDX-1-MT-DROID specializes the pre-trained checkpoint to a single-arm Franka Research 3 platform with AnySkin tactile and joint torque sensing. RLWRLD evaluates two memory-dependent tasks (Swap Cup, Shell Game) and two sensory-dependent tasks (Plug Insertion, Egg Pick & Place) that exercise the Memory Module and Physics Module on a non-humanoid embodiment.
What’s next for RLWRLD
Per-task data requirements vary, RLWRLD observed. Some tasks converge quickly with few demonstrations; others need relatively extensive post-training.
When it comes to the company’s long-horizon planning ability, RLWRLD’s current experiments demonstrate memory-dependent decision-making over short-to-medium interaction horizons. Extending this capability to substantially longer temporal contexts, such as hour-long interactions, remains an important direction for future work.
The company is also targeting zero-shot ability. RLDX-1 achieves strong instruction understanding under our current training and adaptation setting compared to other frontier VLAs, but its zero-shot generalization as a pre-trained policy remains an open direction.
RLWRLD also said it hopes to extend RLDX-1 to the video/world model. RLDX-1 can be extended toward video/world modeling, where the model learns to predict future visual observations conditioned on language instructions and actions. Such an extension could provide a stronger basis for long-horizon planning and action-conditioned imagination in embodied environments, and it represents a promising direction for future work, said the company.




Tell Us What You Think!