Industrial robots deployed today across various industries are mostly doing repetitive tasks. The overall task performance hinges on the accuracy of their controllers to track predefined trajectories. The ability of robots to handle unconstructed complex environments is limited in today’s manufacturing.
Two examples are flexible picking of previously not encountered objects or the insertion of novel parts in assembly tasks. There are numerous examples of spectacular robot demonstrators exhibiting dexterity and advanced control, e.g. robot Fanta challenge, or robots playing ping pong. However, these applications are hard to program and maintain, usually they are the output of a PhD thesis, and they haven’t made the leap into manufacturing.
Endowing machines with a greater level of intelligence to autonomously acquire skills is desirable. The main challenge is to design adaptable, yet robust, control algorithms in the face of inherent difficulties in modeling all possible system behaviors and the necessity of behavior generalization.
Reinforcement learning (RL) methods hold promise for solving such challenges, because they enable agents to learn behaviors through interaction with their surrounding environments and ideally generalize to new unseen scenarios.
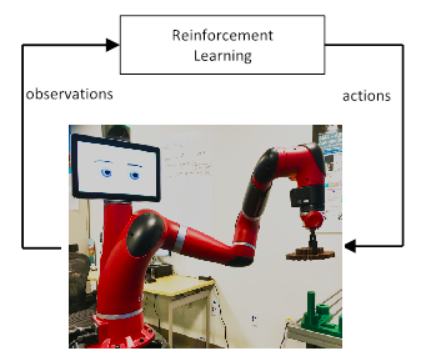
Figure 1: Reinforcement learning loop for robot control. (Credit: Siemens)
Reinforcement learning
RL is a principled framework that allows agents to learn behaviors through interactions with the environment. As opposed to traditional robot control methods, the core idea of RL is to provide robot controllers with a high-level specification of what to do instead of how to do it. Thereby, the agent interacts with the environment and collects observations and rewards.
The RL algorithm reinforces policies that yield high rewards, see Fig. 1. RL can be distinguished in value-function-based methods and policy search. In policy search, robots learn a direct mapping from states to actions. In value-function-based approaches, robots learn a value function, an intermediate structure that assesses the value of an explicit state, and derive actions from the value function.
Both policy search and value-function-based approaches can either be model-based or model-free. Model-free methods do not consider the dynamics of the world. Model-based methods incorporate a model of the world dynamics, which is learned from data as well.
Reinforcement learning for industrial applications
As we can see, robot control methods can be grouped along a continuum where on one end we find “rigid” feedback control laws, which are hand-engineered, incorporate domain knowledge and the control structure is not adapted by data. On the other end of the spectrum we have RL methods, which allow learning control policies purely from observed data. Both methods have advantages and disadvantages.
Traditional feedback control methods can solve various types of robot control problems very efficiently, such as trajectory tracking in free space, by capturing the structure with explicit models, such as rigid body equations of motion. However, many control problems in modern manufacturing deal with contacts and friction, which are difficult to capture with first-order physical modeling. And if higher-level reasoning is required (where to pick in bin picking problems, for example) current robot controllers lack flexibility. Applying feedback control design methodologies to these kinds of problems often results in brittle and inaccurate controllers, which have to be manually tuned for deployment.
RL, on the other hand, can, in principle, learn any control structure. However, for real-world robots, the continuous exploration space is large and, hence, large amounts of data and, therefore, long training times are required. Moreover, unlike conventional feedback control, convergence and stability statements are difficult to derive for RL methods.
Just to name two recently popularized use cases for both control methods: Boston Dynamics is known for deploying conventional feedback control laws (more precisely Funnel Control) for all its well-known demonstrations. Google, on the other hand, has shown that RL is capable to arrive at a robot controller for bin picking simply through trial and error. However, several months of training on a robot farm were required to achieve the required control performance.
After realizing that robot control methods comprise a continuum, where the underlying dimension is how much influence online data has on shaping the control algorithm, it seems that best control performance for flexible manufacturing has to combine both traditional control theory and data-driven RL. Traditional control can provide guarantees in safety and performance, while RL can bring flexibility and adaptability, if tuned correctly. In a way, RL removes the specificity needed at the engineering stage, where controls are designed. It targets to achieve the same performance than a carefully engineered feedback control algorithm, but without the need of tedious programming and rules.
We suggest decomposing robot control pipelines, which consist of perception, state estimation, control etc, into sub-problems that can be explicitly solved with conventional methods and sub-problems, which are approached with RL. The final control policies are then superpositions of both data-driven components and control policies from first-order models. Our approach combines the benefits of traditional control theory (e.g. data-efficiency) with the flexibility of RL. For example, position control is taken care of by a PID controller, and RL contributes the control part that deals with friction and contacts. We have conducted studies on different industrially relevant use cases, which amongst others include robots to perform real-world assembly tasks involving contacts and unstable components.
Figure 2 illustrates two assembly use cases, where conventional feedback control was combined with RL to solve complex assembly tasks in a flexible manner. Subfigures (a) and (b) show how a gear wheel is placed on a shaft. The use case is part of the Siemens Robot Learning Challenge. The robot required less than seven iterations to learn the required control policy. Subfigures (c) and (d) show a different use case for which the same control algorithm was used as for (a) and (b). Again, after less than seven iterations, the robot learned the control policy.

Figure 2: Insertion use cases solved with a combo of conventional control and reinforcement learning. (Credit: Siemens)
A challenge persists in this approach. Seven iterations may seem reasonable for lab setups, but they entail an inherent risk, as every iteration in a friction-rich environment has the danger to damage the part in contact with the gripper. Accurate sensors and adequate constrain management can alleviate the problem. Those are better handled in the pipelines that use traditional control, and can filter the output of the RL commands. Note that a certain amount of engineering is still needed to ensure that the robot is not in a lock position, unable to move because of the constrains. In these situations, calling a human for help may be the best course of action. In addition, in order to reduce the number of real world iterations, novel approaches in simulation to reality gap (sim2real) have been proven to accelerate the learning.
As a conclusion, we believe the current hype of reinforcement learning around robotic applications has a valid motivation; however, it is not the main ingredient to guarantee success. End-to-end learning approaches have shown poor performance in tasks that require precision. In an analogy that we like to make, if you want to make a chocolate cake, chocolate (reinforcement learning in this case) is not the main ingredient. You still need eggs, flour, etc. These “less-sexy” ingredients are in our case traditional control approaches. They are the base to build a successful flexible robotics application.
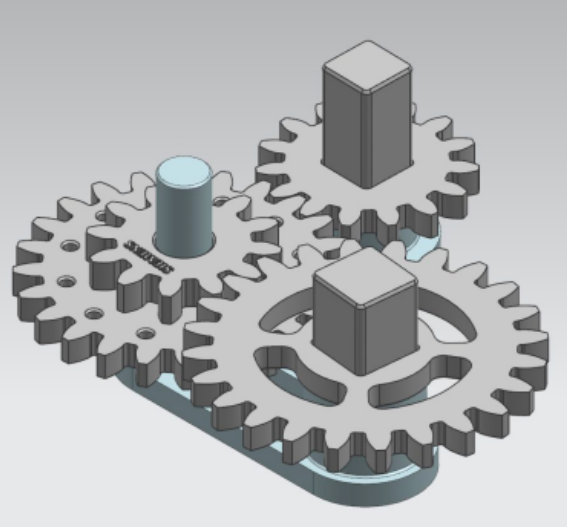
Figure 3: Siemens Robot Learning Challenge. (Credit: Siemens)
Robot Learning Challenge
We strongly believe that to accelerate robot learning research and its adaption in industry, we need a benchmark for the research community. We have seen that the ImageNet benchmark, which was introduced by Fei Fei Li in 2009, became the catalyst for image classification with deep learning. Machine performance for classification surpassed human capabilities in 2015. Benchmarks accelerate research because they facilitate reproducibility and allow comparison of research.
In the case of robot picking, this work goes in the right direction. In the case of robotic assembly, there is still need for globally accepted benchmarks. Therefore, we introduced the Siemens Robot Learning Challenge at the first Conference for Robot Learning in 2017. The challenge consists of a gear assembly task as seen in Fig. 2 (a) and (b) and Fig. 3. Details and CAD models for 3D printing can be obtained here.
Since the inception of our challenge, we have seen a variety of research work being published that is based on the Siemens Robot Learning Challenge – see examples here and here. We would like to encourage the community to try the challenge and help us refine it to cover as many cases as possible. Only with a common, easily reproducible benchmark can the robot learning community start building pipelines and tools that built on top of each other. If you have tried it, and want to contribute with your results, feel free to email the authors.

Aparicio
About the Authors
Juan Aparicio is the Head of Advanced Manufacturing Automation at Siemens Corporate Technology in Berkeley, CA. Aparicio has extensive experience managing complex projects, involving hardware and software; and bridging the technology gap between universities and businesses. His areas of interest include advanced manufacturing, advanced robotics, connected cars, Industry 4.0, and cyber-physical systems.
Aparicio is member of the Technical Advisory Committee for the Advanced Robotics in Manufacturing (ARM) Institute in the US and the Project Manager of the Open Process Automation Forum.

Solowjow
Dr. Eugen Solowjow is a Research Scientist specialized in robotics and machine intelligence at Siemens Corporate Technology. He has received his PhD from Hamburg University of Technology (TUHH), Germany. From 2012 to 2017 he was employed as a Research Associate at TUHH and as a visiting researcher at U.C. Berkeley.
Eugen was the technical lead in multiple government funded projects at TUHH in the field of robotics. He co-authored 20+ peer-reviewed publications (IROS, ICRA, RA-L, AuRo etc.) and has received multiple scholarships, fellowships, and academic awards.




Tell Us What You Think!