Knowing the 3D position and orientation of objects, often referred to as 6-DoF pose, is a key component to robots being able to manipulate objects that aren’t in the same place every time. NVIDIA researchers have developed a deep learning system, trained on synthetic data, that can do just that using one RGB camera.
NVIDIA said its Deep Object Pose Estimation (DOPE) system, which was introduced this morning at the Conference on Robot Learning (CoRL) in Zurich, Switzerland, is another step toward enabling robots to work effectively in complex environments. Read the paper “Deep Object Pose Estimation for Semantic Robotic Grasping of Household Objects” for more in-depth detail.
Stan Birchfield, a Principal Research Scientist at NVIDIA, told The Robot Report that with NVIDIA’s algorithm and a single image, a robot can infer the 3D pose of an object for the purpose of grasping and manipulating it. Synthetic data has the advantage over real data in that it is possible to generate an almost unlimited amount of labeled training data for deep neural networks.
“Real data needs to be annotated by hand. It’s very hard for a non-expert to label these images,” Birchfield said. “We’ve been looking at how to train networks with synthetic data only for some time.”
One of the key challenges of synthetic data, NVIDIA said, is the ability to bridge the “reality gap” so that networks trained on synthetic data operate correctly with real-world data. NVIDIA said its one-shot deep neural network, albeit on a limited basis, has accomplished that. Using NVIDIA Tesla V100 GPUs on a DGX Station, with the cuDNN-accelerated PyTorch deep learning framework, the researchers trained a deep neural network on synthetic data generated by a custom plugin developed by NVIDIA for Unreal Engine, which is publicly available for other researchers.
“Specifically, we use a combination of non-photorealistic domain randomized (DR) data and photorealistic data to leverage the strengths of both,” NVIDIA researchers wrote in their paper. “These two types of data complement one another, yielding results that are much better than those achieved by either alone. Synthetic data has an additional advantage in that it avoids overfitting to a particular dataset distribution, thus producing a network that is robust to lighting changes, camera variations, and backgrounds.”
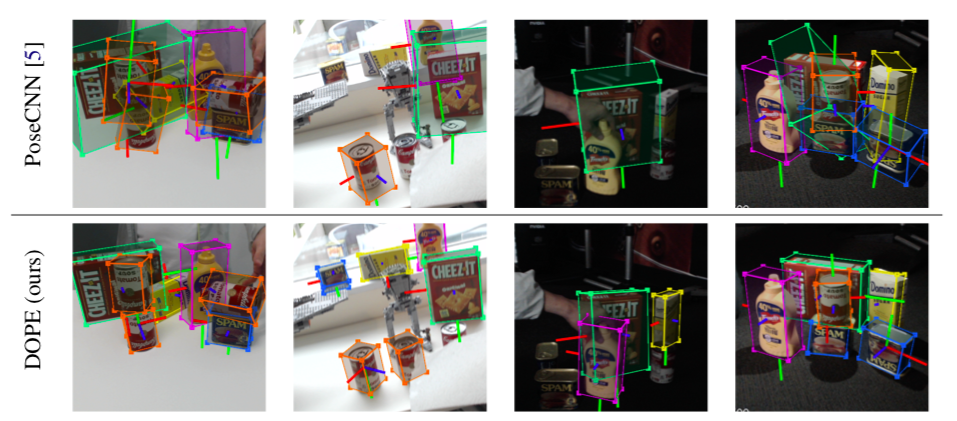
Figure 3: Pose estimation of YCB objects on data showing extreme lighting conditions. TOP: PoseCNN [5], which was trained on a mixture of synthetic data and real data from the YCB-Video dataset [5], struggles to generalize to this scenario captured with a different camera, extreme poses, severe occlusion, and extreme lighting changes. BOTTOM: NVIDIA’s DOPE method generalizes to these extreme real-world conditions even though it was trained only on synthetic data; all objects are detected except the occluded soup can (2nd column) and three dark cans (3rd column).
Testing NVIDIA’s system
The system approaches its grasps in two steps. First, the deep neural network estimates belief maps of 2D keypoints of all the objects in the image coordinate system. Next, peaks from these belief maps are fed to a standard perspective-n-point (PnP) algorithm to estimate the 6-DoF pose of each object instance.
To put its pose estimation system to the test, NVIDIA attached a Logitech C960 RGB camera to the waist of a Baxter two-armed cobot from Rethink Robotics. The Logitech camera was calibrated to the robot base using a standard checkerboard target visible to both the Logitech camera as well as the wrist camera. The parallel jaw gripper moves from an opening of approximately 10 cm to 6 cm, or from 8 cm to 4 cm, depending on the thickness of the rubber tips installed.
The researchers used five objects, placed among clutter, in four different locations on a table in front of the robot, in three different orientations at each location. The Baxter robot was instructed to move to a pre-grasp point above the object, then execute a top-down grasp, resulting in 12 trials per object. Of those 12 attempts, here is the number of successful grasps per object: 10 (cracker), 10 (meat), 11 (mustard), 11 (sugar), and 7 (soup).
NVIDIA said the round shape of the soup can caused some issues with the top-down grasps. When the researchers repeated the experiment with the can of soup lying on its side, the number of successful grasps increased to 9 of 12 attempts.
Rethink Robotics closed its doors on October 3. The IP has since been acquired by HAHN Group, a German automation specialist that will continue to manufacture and sell the Sawyer cobot. We asked Birchfield for his thoughts on the Baxter robot.
“As a researcher, we’ve been very happy with Baxter. It has a large amount of capability for the price,” said Birchfield. “Baxter doesn’t know the company went out of business. But our robotics lab has a variety of robots that will enable us to test different robots going forward.”
Next steps for NVIDIA
At press time, Birchfield said the system was only trained on those five objects. The researchers are working off the well-known Yale-CMU-Berkeley (YCB) Object and Model Set, which consists of 77 everyday items. Birchfield said there is no limit to the number of objects the system can detect, but the researchers “took a subset that represents a variety of different sizes and shapes that are easily accessible for people to go to the store and try out.”
Birchfield said this system will enable other robotics developers to get a jumpstart on their projects by solving a key part of the perception problem.
“Robotics is such a multi-disciplinary field that researchers have a challenge in from of them because of time,” Birchfield said. “Often times with perception, folks will use AR tags to help solve that problem. Our technology will help them get one step closer to the real world without using AR tags.”
NVIDIA said the next steps are to increase the number of detectable objects, handle symmetry and incorporate closed-loop refinement to increase grasp success.




Tell Us What You Think!